

Not just a matter of Gbps - Classifying DDoS Attacks
Distributed Denial of Service (DDoS) attacks are becoming prevalent in our daily life. Just in the past ten years, things have changed significantly – from the forgotten hacktivist collective Anonymous through booters, to present-day organized crime using DDoS as leverage for extortion. Just like boiling the proverbial frog, this topic crept up on all of us, and there is much misunderstanding resulting from partial reporting and not a clear understanding of the topic as a whole. While most people are used to seeing DDoS attacks expressed in Mbps or Gbps, this is not totally accurate as it's only one characteristic of the attack. Some of the attacks like Slowloris will result in a drop in traffic on the link graphs. There are several other important characteristics describing those attacks, and those are packets per second (pps), connections per second (cps), queries per second (qps), the protocol used, etc.
In this article, we attempt to create some order by classifying the different attacks and elaborating on particular concepts that appear to be commonly misunderstood.
Number of sources
The first and most often neglected detail is the number of sources sending traffic. This is the difference between a Denial of Service and Distributed Denial of Service attack and is a frequent source of confusion and miscommunication. One of the most common misconceptions is that the source of a packet can be determined by its IP address – no, I am not crazy. Let me explain. There is a difference between where the packet came from and what the return address (aka “source IP) says. During regular operation, the operating system will fill in the source IP address in a packet with the correct value; however, this is not guaranteed when malicious intent is involved. The attacker can insert any value they wish. Ultimately, this will allow the attacker to send many packets from one host using multiple source IP addresses, making it appear it is coming from different places on the Internet. A typical example is the SYN Flood attack. One source could send SYN packets with randomly generated source IP addresses to prevent the victim from filtering a single IP address source.
The opposite is true as well; the attacker can use many hosts to generate packets that appear to be coming from the same host. This is typical for the reflected attacks, particularly Reflected DNS attacks, as well as, the gaining popularity now, ACK Flood when a CDN is used for reflections. More on that in another blog post.
To summarize, if the attack comes from a single system, regardless of the variety of IP addresses, the attack is direct.

If the attack comes from multiple sources, then it is a Distributed Denial of Service attack. In the following pictures, the first one depicts an attack from a network of infected systems while the second shows a reflected attack.
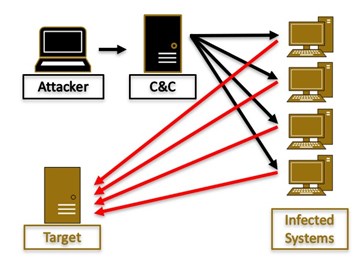
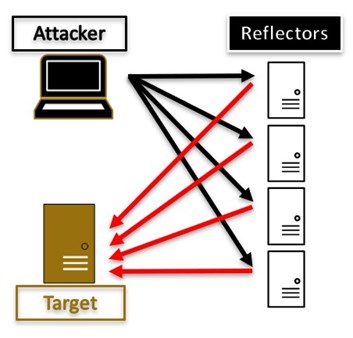
The reason this distinction is important is that mitigation and investigation be conducted in a different way.
Reflected and direct attacks
Another way to classify attacks is based on who controls the system generating the traffic. In direct attacks, the attacker controls the traffic originator, so at minimum, the system is infected with some type of malware. This is what people usually envision when they think of a botnet executing a DDoS. However, the system generating the traffic may not be under direct attacker control; but instead, it is running specific services which are misconfigured and allow traffic to be reflected. The term reflection has a particular meaning, and it means that the attacker can send a packet with a spoofed source IP address equal to the one of the victim. Traditionally those attacks have also used amplification, which is when the response is often many times bigger than the query; thus, reflected attacks traditionally are also amplification ones. For those two effects to work, the abused protocol needs to allow for a single packet query and provide for large answers. For example, a DNS query over UDP perfectly fits in one packet, and if the source IP is spoofed, the DNS server will send its response to the victim. Furthermore, if the answer is large, the victim will receive a large number of bytes segmented in packets. Similarly with NTP, or Memcached.
An attack worth noting is the reflected ACK flood. Like in the case above, the attacker would send a packet with a spoofed source IP matching one of the victims and set the SYN flag on. This will result in immediate reflection of this same size packet having its ACK (and SYN) flags set. Depending on the TCP stack the reflector may respond with up to six ACK packets, which gives 65x amplification. However, this is not the real benefit of the attack. This attack is predominantly used to conceal the IP address of the attacker and very often uses large CDNs for the reflection. This is because the CDNs do not usually monitor for this type of behavior and have sufficient capacity so their performance is not impeded. Even if it is detected the CDN cannot rate-limit or stop responding with SYN-ACK as this is its core function.
Volumetric attacks
Just as the name suggests, those attacks have to do with sending a large volume of data, packets, connections, or queries.
Data on its own can saturate the connecting links to the service, thus preventing traffic from reaching that site. Using protocols on top of TCP would generally yield lower success as TCP requires acknowledgments and has congestion control. This is why the attacks that deliver floods of data predominantly use UDP, and in rare cases ICMP. Examples of such attacks would be reflected DNS, reflected NTP, Memcached, and ping flood.
High number of packets exploit the ability of the routing equipment, load balancers, and firewalls to make decisions based on packet header data. When speaking about routers, we need to understand what types of tasks are executed on them. The first, most important, and obvious one, is routing. For every packet from a new connection, the router will have to decide which output interface to route the packet to. This will include consulting the routing table and can also include uRPF or other policy checks. All of those require the engagement of the routing processor (aka CPU). Once this problem is solved, the router will communicate the output interface to the incoming interface, and then the packets will be switched by hardware and directly DMA-ed [https://en.wikipedia.org/wiki/Direct_memory_access] without engaging the routing processor. While this vector can be used for DDoS, it is rare, as modern devices are sized and behave fairly well at that level.
The problem, however, occurs when the device needs to make other decisions, for example, a load balancer needs to find what session a particular packet belongs to, or a firewall needs to scan through many rules, or a device needs to consult a NAT table. The majority of those expensive tasks involve the management of the Transport layer state, so they are usually executed over TCP. Just to name a few: RST Flood, FIN Flood, XMAS Flood.
At this point, it is evident that firewalls should not be positioned at the front of the network stack as they will be the first component to be denial-of-serviced if the attacker knows what they are doing.
High connection rate
While this group of attacks is no longer popular, it’s worth mentioning. During a Connection Flood, the attacker would rapidly open and close connections which in the past would cause socket exhaustion. This was caused by the TIME_WAIT constant, which mandated that a socket cannot be reused for 60 seconds under particular circumstances. If an attacker cycled through several sockets quickly, they would all be in TIME_WAIT state, preventing new connections from being established. One variation of this attack is to engage HTTPS and temporal key negotiation. Since this requires complex asymmetric cryptography calculations, it would consume compute resources.
High query rate
In this class of attacks, the attacker repeatedly sends queries to URLs which take larger resources to process. For example, one may request their bank statement over the past ten years, which will require an expensive database query going over a large amount of data.
Conclusion
It is essential to understand that computer systems are comprised of a chain of dependent systems, so it is only necessary to disrupt a system in a non-redundant chain to deny service to an application. And thus, the attacker would use the one that requires the least amount of effort or resources. This is why many DoS attacks are very simple from a technology point of view, as they only need to affect one component to stop a larger system from functioning. In many cases, they also depend on high rates of packets or traffic volume, but they do not need that in some cases. As you can see, there is a great variety of DDoS attacks and this is true for the ways they can be classified, which far exceeds the scope of this blog. I've published a comprehensive DDoS Mitigation training through the Forum of Incident Response and Security Teams (FIRST). In this training, you can find a very exhaustive classification by OSI layer and a detailed explanation of each attack.

